Oracle数据库删除重复数据
由于越来越多的应用不采用数据库层的数据完整性约束(主要指外键约束和唯一性约束),那么也就会有越来越多的脏数据存在。
场景
假设:有如下A表(文章表)id为数据库主键,doc_id为业务上的主键用来确定唯一一篇文章
| id | doc_id | doc_name | doc_link | doc_author | update_time |
|---|---|---|---|---|---|
| 1 | A000001 | 架构技术演进 | test.com/a000001.html | 张三 | 2016-03-04 |
| 2 | A000001 | 架构技术演进 | test.com/a000001.html | 张三 | 2016-03-05 |
| 3 | B000002 | 为什么使用微服务 | test.com/b000002.html | 李四 | 2017-01-01 |
| 4 | B000003 | 分布式架构 | test.com/b000003.html | 王五 | 2017-03-01 |
假设:有如下B表(我阅读的文章表)id为数据库主键,read_doc_id业务上确定读了哪一篇文章,read_update_time 为最后一次阅读时间
| id | user_id | read_doc_id | read_update_time |
|---|---|---|---|
| 1 | 11101 | A000001 | 2017-07-01 |
查询语句
select
a.doc_name,
a.doc_link,
a.doc_author
b.read_update_time
from a, b
where
a.doc_id = b.read_doc_id and b.user_id = '11101'
页面结果
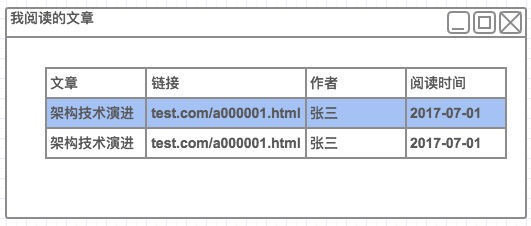
问题来了出现了重复的数据,原因是A表数据重复
如何定义重复
这依赖于我们面对的业务
-
业务主键重复
这种情况是指如A表中doc_id一旦重复,无论其他列是否重复都定义为重复 -
数值一致重复
想象一下A表没有id列并且其他列的值都一样
如何确定要删的行
通过count和having来看有哪些行是重复的
select a.doc_id, count(1) from a group by a.doc_id having count(1) > 1
得到下面的结果
| doc_id | count(1) |
|---|---|
| A000001 | 2 |
| B000002 | 1 |
| B000003 | 1 |
重点是怎么删
1.业务主键重复
需要挑出一条来删,比如保留id主键最大的,或者保留update_time最近的,这完全取决你的实际情况。
删除重复数据的思想是利用业务主键确定要删除的数据集合,保留集合中最后一条数据即可
create or replace procedure REMOVE_DUPLICATE_DATA is
i NUMBER; -- 循环标记变量
begin
--根据业务主键循环所有重复数据
for temp in (select a.doc_id, count(1) as c
from a
group by a.doc_id
having count(1) > 1) loop
i := 0;
--利用定位到的重复数据查到所有等待被删除的实际主键
for tempx in (select id
from a
where a.doc_id = temp.doc_id
order by procinst_id) loop
--需要保留一个不删除
if (i < temp.c - 1) then
--依次删除
delete from a where id = tempx.id;
i := i + 1;
end if;
end loop;
end loop;
commit;
end;
2.数值一致重复
随便删哪一条,需要使用rownum
思想和第一种情况一样,但是没有主键的数值类重复找不到删除的唯一性条件所以需要加个rownum即可。
最佳实践
第一条. 数据主表该加唯一性约束的要加上
第二条. 没把握的insert()改成saveOrUpdate()
